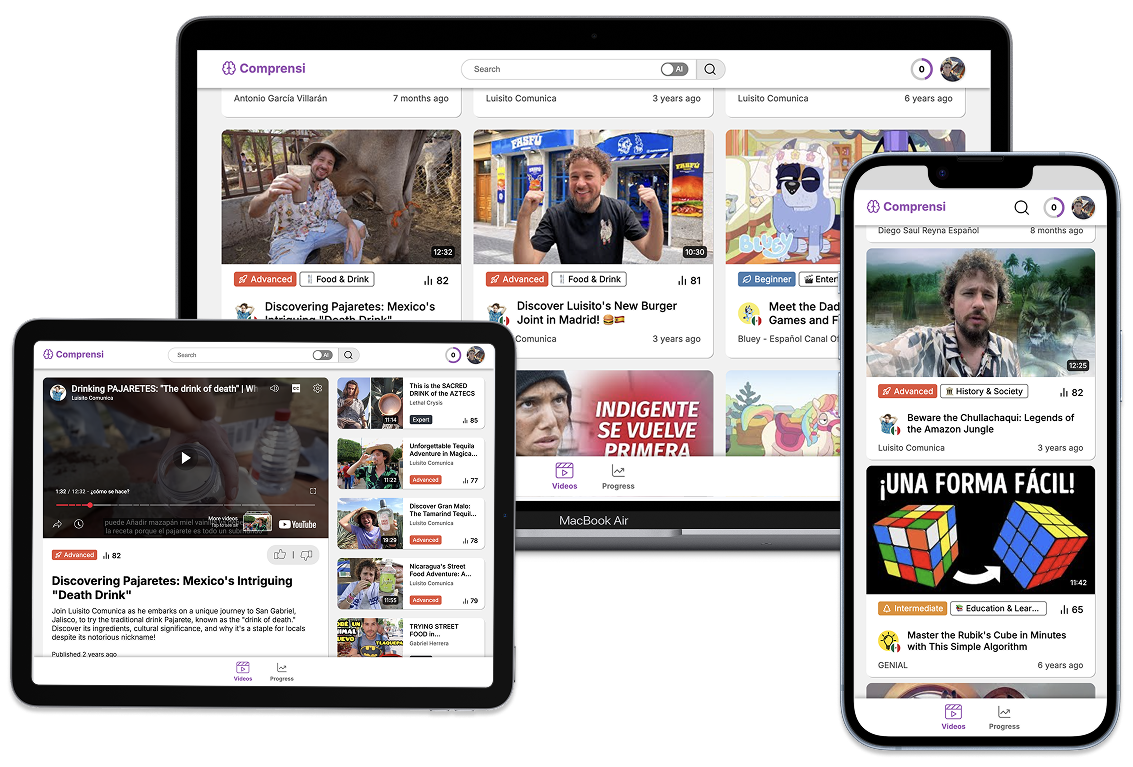
Comprensi curates internet content and uses machine learning to predict its difficulty in a language learning context. This provides language learners with a 'lens' to filter and focus on material that matches their proficiency.
As a solo startup endeavour, I am responsible for everything - from dataset curation to model training, from design to frontend implementation, from building the backend to infrastructure design and deployment.
The model used for language difficulty prediction is an ensemble model combining Logistic Regression, Random Forest and Gradient Boosting. The model was trained using the python library scikit-learn, achieving
an F1 Score of 74.53% (near human baseline performance of 75.79%), ensuring users consistently find content matched to their proficiency, as confirmed by user feedback.
Next.js powers the architecture, evolving from static AWS S3 deployment to server-side rendering on Vercel. Features a hybrid API: Next.js routes for authenticated requests, AWS serverless for public endpoints.
An AWS pipeline (S3, SQS, Lambda, DynamoDB) handles content ingestion with Python ML inference and ChatGPT for content categorisation, translated titles/summaries, and semantic search.